The Pfam database is large collection of multiple sequence alignments and hidden Markov models (HMMs) covering many common protein domains and families.
Pfam aims to provide a complete and accurate classification of protein families and domains for a wide range of users: experimental, structural, and computational biologists. It also allows users to submit protein or DNA sequences to search for matches to families in the database.
RepeatsDB data supports the definition of Pfam HMM profiles through the refinement of repeat unit defintions. In addition, the RepeatsDB classification is designed in collaboration with Pfam curators.
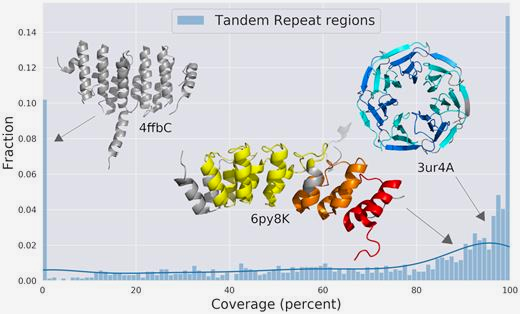
Pfam coverage of repeat regions in UniProtKB entries from RepeatsDB. Three examples are shown represented by their PDB structures. Read related paper.